国内AI大模型盘点!谁更有潜力?
当下,百度文心大模型、华为盘古大模型、腾讯混元大模型、阿里通义大模型正在加快向GPT模型追赶的步伐。#GPT产业链行情持续爆发##大模型军备竞赛白热化##热度重燃!AI行情或进下半场#
那么什么是大模型,其底层逻辑是什么,有哪些玩家,市场空间有多大,我们来一探究竟。
一、什么是AI大模型 $拓维信息(SZ002261)$$鸿博股份(SZ002229)$$科大讯飞(SZ002230)$
近半年AI大模型持续推出,从ChatGPT、文心一言在多场景广泛深入地应用,标志着AI大模型时代已来临。
那么什么是AI大模型?大到什么程度才能称之为大模型?AI大模型是指一个庞大复杂的神经网络,需要通过存储更多的参数来增加模型的深度和宽度,从而提高模型的表现能力,参数从百亿起步,对大量数据进行训练并产生高质量的预测结果。最著名的AI大模型是OpenAI的GPT-3模型参数规模达1750亿,PaLM-E的参数规模更是达到了5620亿。
相比传统AI模型,大模型的优势体现在于:
(1)解决AI过于碎片化和多样化的问题。大模型采用“预训练 下游任务微调”的方式,首先从大量标记或者未标记的数据中捕获信息,将信息存储到大量的参数中,再进行微调,极大提高模型的泛用性。
(2)具备自监督学习功能,降低训练研发成本。可以将自监督学习功能表观理解为降低对数据标注的依赖,大量无标记数据能够被直接应用。这样一来,一方面降低人工成本,另一方面,使得小样本训练成为可能。
(3)摆脱结构变革桎梏,提高模型精度上限。随着神经网络结构设计技术逐渐成熟并开始趋同,想要通过优化神经网络结构从而打破精度局限变得困难。而研究证明,更大的数据规模确实提高了模型的精度上限。
二、我国主要大模型盘点
目前中美之间围绕大模型的研发和落地展开竞争。国内大模型厂商主要包括百度、腾讯、阿里、商汤、华为等企业,也有智源研究院、中科院自动化所等研究机构,同时英伟达等芯片厂商也纷纷入局。
数据、算法、算力是AI发展的驱动力,其中数据是AI发展的基石,中国数据规模增速或排名全球第一。据IDC统计,中国数据规模将从2021年的18.51ZB增长至2026年的56.16ZB,年均增长速度CAGR为24.9%,增速位居全球第一。
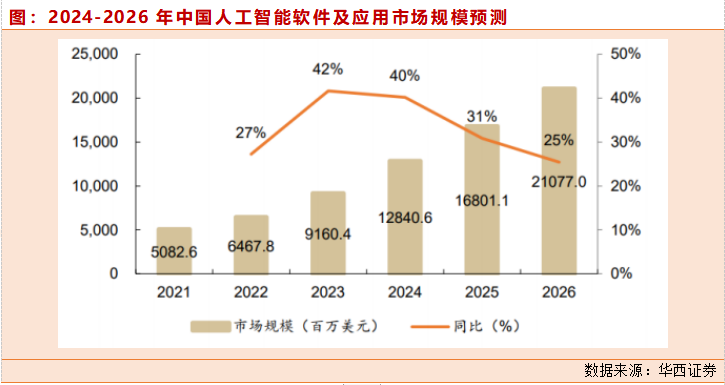
1、百度:文心一言大模型,AI应用场景全覆盖
2023年3月16日,百度官方发布“文心一言”。“文心一言”是百度研发的知识增强大语言模型,拥有文学创作、商业文案创作、数理逻辑推理、中文理解和多模态生成五大能力。文心一言在百度ERNIE及PLATO系列模型基础上研发而成,关键技术包括监督精调、人类反馈的强化学习、提示、知识增强、检索增强以及对话增强。其中,百度在知识增强、检索增强和对话增强方面实现技术创新,使得文心一言在性能上实现重大进步。

百度经过11年积累了全栈人工智能技术,从芯片层、框架层、模型层到应用层。这四层之间形成层到层反馈、端到端优化,尤其是模型层的文心大模型和框架层的飞桨(产业级开源开放平台),在开发文心一言的过程中,它们的协同优化起到了至关重要的作用。模型层的文心大模型包括NLP大模型、CV大模型和跨模态大模型,在此基础上开发了大模型的开发工具、轻量化工具和大规模部署工具,而且支持零门槛的 AI 开发平台以及全功能AI开发平台。
百度大模型相关标的:汉得信息、东软集团、宇信科技、致远互联、软通动力、银之杰、风语筑、掌阅科技、蓝色光标等。
2、腾讯:混元AI大模型,加速大模型应用落地
腾讯2022年底发布国内首个低成本、可落地的NLP万亿大模型:混元AI大模型。HunYuan协同腾讯预训练研发力量,旨在打造业界领先的AI预训练大模型和解决方案,以统一的平台,实现技术复用和业务降本,支持更多的场景和应用。
当前HunYuan完整覆盖NLP大模型、CV大模型、多模态大模型、文生图大模型及众多行业、领域任务模型,自2022年4月,先后在MSR-VTT、MSVD等五大权威数据集榜单中登顶,实现跨模态领域的大满贯;2022年5月,于CLUE(中文语言理解评测集合)三个榜单同时登顶,一举打破三项纪录。基于腾讯强大的底层算力和低成本高速网络基础设施,HunYuan 依托腾讯领先的太极机器学习平台,推出了HunYuan-NLP1T大模型并登顶国内权威的自然语言理解任务榜单CLUE。
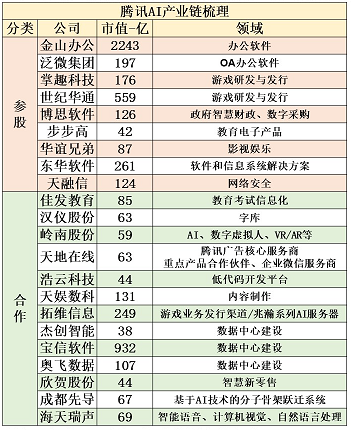
腾讯大模型相关标的:博思软件、世纪华通、掌趣科技、常山北明、四维图新、泛微网络、长亮科技等。
3、阿里:通义大模型,开源释放大模型应用潜力
阿里达摩院一直以来深耕多模态预训练,并率先探索通用统一大模型。阿里达摩院于2021年发布使用512卡V100GPU实现全球最大规模10万亿参数多模态大模型M6,并于2022年发布最新通义大模型系列。通义大模型注重开源开放,首次通过“统一范式”实现多模态、多任务、多结构的运行,并通过模块化设计实现高效率高性能。
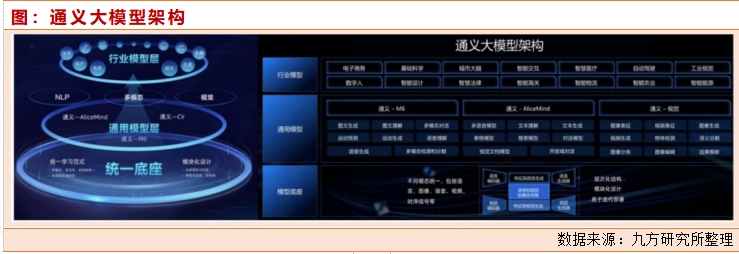
通义大模型整体架构中,最底层为统一模型底座,通义统一底座中借鉴了人脑模块化设计,以场景为导向灵活拆拔功能模块,实现高效率和高性能。中间基于底座的通用模型层覆盖了通义-M6、通义-AliceMind 和通义-视觉,专业模型层深入电商、医疗、娱乐、设计、金融等行业。
阿里大模型相关标的:恒生电子、千方科技、石基信息、众信旅游、卫宁健康、金桥信息等。
4、华为:盘古大模型,打造全栈使能体系
2021年4月25日,在华为开发者大会(Cloud)上,华为云发布了盘古系列超大规模预训练模型。自“盘古大模型”发布以来,已经发展出L0、L1、L2三大阶段的成熟体系持续进化。
L0为基础模型,这类模型无法直接应用到行业场景中,需要与行业数据结合,混合训练得到行业大模型。其中包括 NLP大模型、CV大模型、多模态大模型、科学计算大模型等基础大模型;
L1为行业模型,行业模型可以直接在具体细分场景进行部署,由此也就得到了细分场景模型,比如气象、矿山、电力等行业大模型;
L2为细分场景模型,比如电力行业的无人机巡检、金融违约风险识别模型等。

华为大模型相关标的:拓维信息、特发信息、润和软件、神州数码、宝兰德、创意信息、科蓝软件、软通动力、赛意信息等。
三、总结
我们认为,各大巨头目前在大模型技术上基本同源,且都具有资金、算力、人才、数据等发展条件,未来有望成为我国大模型的第一梯队。
各家在应用场景上各有所长:百度具有搜索、小度智能音箱等应用场景;腾讯具有微信、QQ、游戏等应用场景;阿里具有电商、钉钉等应用场景;华为在2B应用方面独具优势。
未来各家将结合自身优势,发力大模型研发及应用落地,我国的大模型产业将迎来快速发展阶段。
风险提示:本文中提及的相关个股基于公开数据整理,仅供参考!投资者应独立决策并承担投资风险。
本文作者可以追加内容哦 !